
Bir onceki "next-gen unleashed" yazisini "Phil Spence'in aletin gucu Xbox One X'in 4 kati olacak" iddasini inceleyecegimizi belirterek bitirmistik. Ozellikle X1X'in GPU performansina bakarsak, bu cok iddali bir soylem aslinda. Ne de olsa eger Xbox One X'in GPU'yu 4 kat buyuteceksek, bu 24 Gflops'luk bir hesap gucune ve 1.3 TByte/sn'lik bir hafiza erisimi anlamina geliyor ki bugun en yuksek performans GPU'larda bile bu rakamlar yok. Yine de "yok yav, bu mumkun degil" deyip kestirip atmak yerine, bunun ne kadar mumkun olabilecegine bakacagiz bu yazida.. Ama bunun icin ilk once X1X GPU'sunun sahip oldugu Graphics Core Next (GCN), daha sonra da yeni konsollarda olacak RDNA-Navi mimarisine bakmamiz gerekiyor... GCN ile baslayalim....
Graphics Core Next (GCN).. Yada artik Graphics Core Previous?

AMD'nin GCN mimarisini 2010'larin basinda uc tane ana hedef etrafinda tasarlamisti:
- GPU kaynaklari ile normal hesap islemlerini (compute tasks) en az silikon ile en fazla miktarda yapilabilmek
- Grafik islemleri ile normal hesap islemlerini verimli bir sekilde bir arada yapilabilmek (ve bu sayede daha once bilgisayar ana islemcisi uzerinde calisan ve paralel isleme gerektiren bir cok islemi grafik ile paralel sekilde GPU uzerine tasimak).
- CPU ile GPU'nun ortak bir hafiza alani tanimlayabilmesine ve dahasi CPU ve GPU'nun tam etkilesimine olanak saglamak.
AMD bu hedefler etrafinda tasarladigi GCN mimarisini ilk kez 2012'de 78x0 serisi grafik kartlari ile tanitti. O zaman cok buyuk bir atlamayi temsil ettigi icin oldukca basarili olan bu mimarinin ikinci generasyonu ise 2013'de piyasaya cikan hem Xbox One, hem de PS4'de kullanilmisti. Her iki konsolun mid-gen guncellemeleri de bazi iyilestirmelere ragmen ayni ozellikleri tasimaktadir. AMD, 2017'ye kadar bu mimariyi 3 kere daha guncellemistir. Bugun piyasadan alabileceginiz Radeon RX5x0 serisi (4. generasyon Polaris) ve Vega serisi (5. generasyon Vega) GCN mimarisi tabanli en guncel video kartlaridir. AMD'nin Arcturus adini tasiyan 6. generasyon yeni bir GCN mimarisi guncellemesi uzerinde calistigi da bilinmektedir. Bu yeni mimariyi tasiyan kartlarin yuksek hesap gucu hedefleyen workstation/server'lar icin 2020'de piyasaya cikaracagi tahmin edilmektedir [1]. GCN mimarisi icin daha detayli bilgi isin su web-linkine bakabilirsiniz [2].
GCN compute islemleri icin cok guclu bir mimari olmasina ragmen grafik islemleri icin de ayni verime sahip oldugunu soylemek maalesef cok dogru olmaz. AMD'nin en guncel GCN mimarisi olan Vega kartlarinda bile Nvidia karsitlari ile karsilastirdigimizda da oyunlar icin genel olarak oldukca buyuk bir performans eksikligi goze carpar. Misal NVidia'nin ~4 Tflops ve 192 GB/sn memory bandwidth'e sahip 1060 serisi GPU'su, AMD'nin 6 Tflops'luk ve 256 GB/sn bandwidth'e sahip Radeon 580 karti ile es gorunur ortalamada.. Benzer sekilde Nvidia'nin ~8.5 Tflops'luk ve yaklasik 320 GB/sn bandwdith'e sahip 1080 serisi GPU'su ile de AMD'nin 12.5 Tflops'luk ve 484 GB/sn bandwidth'e sahip Vega 64 karti kafa kafaya bir performansa sahipdir. Peki AMD'de hesap gucu/hafiza erisimi neredeyse 1.5 kata kadar daha yuksek gorunurken, nasil Nvidia cok daha dusuk gucteki kartlarla AMD ile ayni performansi verebilmektedir? Bu sorunun cevabi aslinda AMD'nin GCN'in ana mimarisini olusturan hesap unitesi (compute unit) ve hafiza mekanizmasini inceledigimizde ortaya cikiyor...
(Yazarin Notu: Bu noktada eger teknik kisimlari "ben almayayim" diyorsaniz, "Peki Ya Performans...." kismina atlayabilirsiniz, ama teknik kisimlar da oldukca ilginc.. O yuzden devam edin derim...)
GCN Hesap Unitesi (Compute Unit)
- her clock'da bir 32-bit sabit/kayan nokta carpma ve bir toplama islemi yapabilen 64 adet aritmetik-mantik unitesi (arithmetic-logic unit (ALU))
- tek data uzerine islem yapan (bu 64 bit double precision kayan nokta islemi de olabilir) scalar unitesi
- bir tane trigonometri/x^y tipi islem unitesi
- hafizadan okuma/yazma yapan unite
- 4 adet texture ornekleyici
- cesitli data ve islem komutlarinin tutuldugu hafiza cacheler
Peki biraz daha detaya dalalim: GCN'deki hesap unitesinin barindirdigi bu 64 vektor ALU unite aslinda 4x16 olacak sekilde 4 adet hesap alt-unitesine bolunur. SIMD16 olarak da adlandirilan bu her alt-unite uzerinde 16 elemanli vektorler uzerinde bagimsiz bir fonksiyon calistirilir. Bu fonksiyonlar AMD sozlugunde wavefront ve uzerinde islem yaptigi tek elemanlar ise thread olarak adlandirlir. Yani ozetle GCN'de ayni anda bir hesap unitesi uzerinde 4 wavefront'a ait program calistirilir ve her cycle'da bu dort adet fonksiyona ait birer komut, fonksiyonun uzerinde calistigi 16 adet elemanlik vektore 16 ALU uzerinde ayni anda uygulanir. Bu 16'lik vektor, 16 elemanli pixel(fragment)/vertex dizisi yada 16 elemana sahip bir hesap vektoru olabilir. Buraya kadar guzel, ama isler simdi karismaya basliyor, demistik ya en az kaynak/silikon ile en fazla isi yapacagiz...
GCN mimarisinde her wavefront aslinda 16 degil 64 elemandan olusmaktadir (Wave64 olarak adlandirilir). Yani her wavefront aslinda 64 pixel(fragment)/vertex dizisi yada 64'luk bir hesap vektorunden olusmasi gerekmektedir. Yani bir CU'ya aslinda 64 tane elemandan olusan bir vektor girer. GCN bir komut calistiracagi zaman bu 64 elemanlik vektoru once 4 parcaya boler ve her komut bu 16 elemanli 4 vektor uzerinde SIMD16 uzerinde sirayla 4 clock cycle'da calisir. Daha sonra yeni bir komut okunur ve o yeni komut da yine benzer sekilde 4 cycle icinde calistirilir, ve bu boyle devam eder. Simdi dikkat ederseniz, her alt-unite icin 4 cycle'da bir yeni bir komuta ihtiyac var ve hatirlarsaniz bir CU'yu da 4 alt-hesap unitesine bolmustuk. Bu da bir CU uzerinde sadece tek bir decoder olmasina olanak tanir.. Decoder ne derseniz; gelen programlardaki siradaki islemin ne olacagini ve bu islemin hangi register/data uzerinde calisacagini cozen birimdir. Her CU uzerindeki tek decoder, her clock icinde sirasi gelen alt-hesap unitesinin komutunu cozer ve bir sonraki alt-uniteye gecer. Bu sekilde aslinda bir CU uzerinde kosan 4 tane is icin sadece tek bir decoder yetmektedir. Epeyce silikon kurtardik..
Bunun disinda bu mimarinin bir baska ozelligi ise ayni anda 4 is paketi calistirabilmesine ragmen her bir alt-unite uzerinde aslinda 10 tane'ye kadar is paketi tutalabilmesidir (bir CU icin toplamda 40). Bunun en buyuk sebebi ise bir is unitesi ana hafizadaki bir dataya erismeye ihtiyac duydugu zaman oldukca uzun bir sure beklemek zorunda kalmasidir. Bu ozellikle GDDR5/HBM Ram ise bekleme suresi yuzlerce clock cycle'i bulabilir. Burada bir alt-hesap unitesini bu sure boyunca dondurmak yerine, GCN mevcut is paketini durdurur, data gelene kadar beklemeye alir ve hali hazirda bekleyen obur is paketlerinden bir tanesini calistirmaya baslar. Boylece bu hesap unitelerini olabildigince bos birakmamaya calisilir.
Aslinda bu mimari genel hatti ile oldukca guzel duruyor. Ozellikle her CU cok fazla silikon alani istemedigi icin ise 14/16nm yari-iletken uretim teknolojisinde 500mm2 silikon alanini asmadan GCN GPU'larda bu CU-hesap unite sayisi 64'e (Vega ve Fiji) ve clock rate'de 1.8 Ghz'e (Radeon 7) yaklasabildigi icin toplamda 13-14 TFlops (saniyede 13-14 trilyon matematik islemi) yapilabilmesi teorik olarak mumkun hale gelmektir. Kagit uzerinde super gozukse de ozellike grafik islemleri icin bu mimari o kadar da verimli olmuyor, neden dersek...
GCN'in Patladigi Nokta
- Eger bir cycle icinde hem carpma hem toplama yapmazsaniz o zaman GPU'yu tam performans kullanmiyor demeksiniz. Bir cok grafik ve compute islemleri matrix-matrix yada matrix-vektor carpma islemleri kullandigi icin bu ozellik kullanilir, ama bu komutlarin kullanilmadigi yerler de az degil ve kullanilmadigi anda hesap gucunun yarisini masada birakiyorsunuz demektir.. Bunun disinda bu mekanizmayi kullanmak icin komutlari uygun siralamada calistirmaniz lazim, yoksa yine tam performans alamiyorsunuz..
- Eger bir Wave64 icine 64 elemanlik bir vektor paketlenemiyorsa is yine de kosturulur. Fakat bu durumda sistem, kullanilmayan elemanlari isaretleyerek o elemanlar icin islem yapmaz. Yani o elemanlara denk gelen ALU'lar bos oturur. Ozellikle fragment/pixel shading'de bu durum bolca oluyor..
- Eger bir Wave64 icinde datanin durumuna gore bir kosullu islem yapilmasi gerekiyorsa, her iki kosulda o kosulu saglayan alt-kumeler uzerinde sirayla kosturulur. (2) numarada oldugu gibi bir kosul kosturuldugu noktada o kosulu saglamayan alt kume isaretlenir ve o elemanlara denk gelen ALU'lar yine bos oturur..
- Eger bir scalar register uzerinde hesaplanmasi gereken bir komut gelirse, komutun sonucu tek cycle'da biterken, tum vektor ALU'lar 4 cycle boyunca yine bos bos otururlar..
- Ozellikle islemler arasi bekleme gereksinimi oldugunda bu bekleme hep 4 cycle katinda olmaktadir.
- Sistem uzerinde scalar, vektor ve trigonometri/x^y islemi yapabilen bloklar birbirinden ayri olmasina ragmen bunlar hic bir zaman paralel calistirilmazlar.
Gordugunuz gibi epey bir durumda aslinda bu yuksek hesap gucu olan uniteler tam kapasite kullanilmazlar, ama sorun sadece burada da bitmiyor.. En dramatigini en sona biraktim: Her CU unitesinde belli bir miktarda bir register dosyasi vardir. Bu GCN mimarisinde bir hesap unitesi icin 64 KB ile sinirlidir. Tum bekleyen 40 adet is icin ayrilmis tum register'lar bu 64 KB icinde tutulmasi gerekmektedir. Ayrica vektor registerlar her zaman 4 elemanli oldugu dusunuldugu icin (grafik girdisi olan pixel'ler icin "RGBA" yada vertexler icin "XYZW") ve her eleman da 4 byte'lik single-precision kayan-nokta rakami olarak tutuldugu icin, toplam register sayisi aslinda sadece 4096 tanedir. Simdi her wavefront ile gelen 64 eleman oldugunu dusunurseniz, ayni anda en fazla 64 tane degisik register tanimlayabilirsiniz, yani bu 64 registeri bekleyen tum islere bolmek zorundasiniz.. Simdi elinizde 40 tane is varsa, bu is basina 1.6 register eder. Bu demektir ki bir task cok daha fazla register kullaniyorsa (ki bu hemen her shader icin gecerli bir durumdur bu), o zaman atayabilecegiz is paketi sayisi epeyce sinirlandi demektir. Misal bir wavefront ortalama boyle 8 register kullaniyorsa o zaman atanabilcek is sayisi bir anda 40'dan 8'e duser. Simdi bir de bu isler hep grafik agirlikli ve texture okuma isteyen isler ise ve siz de hafizadan data bekleyen is yerine baska is atayamiyorsaniz, tum hesap unitesi bir anda bekleme durumunda kalabilir. Bu en fena durum aslinda..
AMD iste bu yuzden aslinda GCN'in en onemli ozelliginin "asynchronous compute" oldugunu one cikarmaya calisiyordu yillardir. Yani diyordu ki, misal bir hesap unitesine bir-iki grafik isi atiyorsaniz, yaninda da hafizaya az erisim yapan ve cok register kullanmayan epey fazla genel hesap isleri de atayin ki bu uniteler tam performans calissin (fizik motoru/AI gibi). Gercekten bunu yapan oyunlar ve cesitli hesap uygulamalari var. Bunlara baktiginiz zaman tum GCN mimariyi tasiyan kartlarin uctugunu goruyorsunuz..Vega 64 de, R580 de bir anda 1080 ve 1060'in fersah fersah onune gecmeye basliyor: Misal Vega 64'un RTX 2070 ile, R580'in de GTX 1070 ile kafa kafaya oldugu oyunlar var... Ama bunlar cok sinirli ve muhtemelen bu tip bir optimizasyon Nvidia icin cok bir avantaj getirmedigi icin de developerlar motorlarini o sekilde tasarlamiyorlar ve bu durum da hem AMD ve haliyle de mevcut konsollarin da elini kolunu yillardir baglamis durumda..
Peki karanlik bulutlari dagitalim artik...
Radeon-DNA Nam-i Diger RDNA...
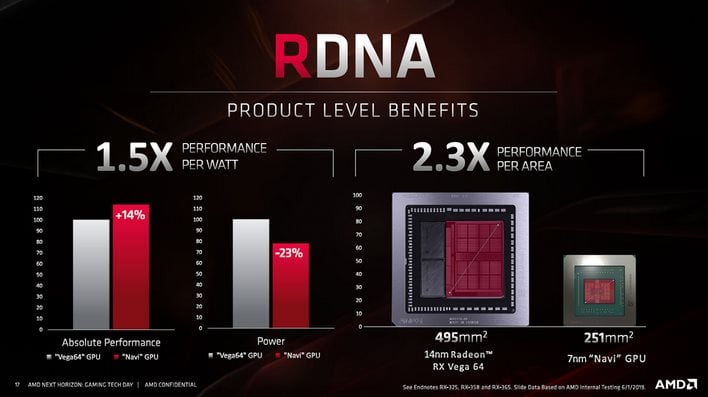
Aslinda epey suredir AMD'nin yol haritasinda Navi serisi de 6. generasyon GCN mimarisi olarak gorunuyordu. Ama muhtemelen son 2-3 yil icerisinde bu yeni mimari uzerinde calismalari oldukca olgun hale geldi ki, son bir sene icinde Navi adi yeni mimari olan RDNA ile anilmaya baslandi. Aslinda bu mimari ile cikan ilk grafik kartlarina (Radeon 5700 serisi) baktigimiz zaman ozellik olarak Vega ile neredeyse birebir ayni oldugunu gorunuyoruz. Nvidia'nin Turing serisinde oldugu gibi "variable rate shading", "ray tracing" yada "neural network inference" islemlerini hizlandirma gibi hic bir yenilik yok. Ama su yukarida yazdigim problemleri gidermek cok daha onemli oldugu icin, ilk generasyon RDNA ile AMD ilk olarak grafikteki performans sorununu cozmeye saldirmis durumda. Peki degisiklikler ne, biz simdi ona bakalim. RDNA'nin aslinda GCN'e gore getirdigi sekiz tane onemli yenilik var:
- Wavefront yapisi olarak Wave64'un yerini Wave32 almis durumda; yani artik bir is paketi 64 eleman yerine 32 elemanli vektorlerden olusuyor. Oyle olunca yukaridaki (2) ve (3)'den olusan kayip olasiligi yari yariya iniyor..
- RDNA, GCN mimarisinin Wave64 paketleri dorde bolme ve SIMD16 uzerinde calistirma mekanizmasi tersine, Wave32 paketlerini 32 tane ALU iceren bir SIMD32 alt-unite uzerinde calisiyor. Yani artik 4 cycle'da 64 eleman uzerinde tamamlanan islem yerine, tek cycle'da 32 eleman uzerinde tamamlanan islemler geliyor. Islemler artik tek cycle'da tamamlandigi icin her alt-unite icin ayri bir decoder var. Yani bir CU uzerinde artik tek bir komut decoder degil, cift decoder calisiyor. Biraz silikon miktarini arttirdik ama komut gecikmesi 4 cycle'dan tek cycle'a indi..
- Komutlar tek cycle'da calistigi icin scalar islemler de tam performans yapilabiliyor. Ozellikle birden cok pespese yapilan scalar islemler artik dortte bir zaman aliyor ve vektor ALU'lardaki bekleme kaybi da yine 4 cycle yerine sadece tek cycle'a inmis durumda. Tabii decoder gibi artik her alt-unitenin artik kendi scalar unitesi de var.
- Artik is paketleri 32'lik elemanlara indigi icin bu register dosyasi uzerindeki baskiyi da epey azaltiyor. Bunun disinda alt unite icin olan maksimum is miktari 10 olarak korunuyor, ama bir CU uzerindeki alt unite sayisi ikiye indigi icin, toplam is sayisi tum CU icin 20'ye inmis durumda. O yuzden yukaridaki orneklerden gitmeye devam edersek, artik maksimum sayi olan 20 is icin 6.4 register varken, 8 register kullanan is paketleri icin de atanabilen is sayisi 8'den 16'ya cikmis durumda. Yani aslinda bir CU'u cok daha verimli kullanmak mumkun hale gelmis ve beklemelerde arayi dolduracak isleri bulmak daha kolaymis. Buradaki kayip da ciddi azalacak demektir.
- Bu yeni mimari de iki hesap unitesi aslinda bir "Work Processing Group (WGP)" olan bir yapi altinda toplaniyor ve iki hesap unitesi icin register dosyasi, aslinda bazi sinirlamalar ile x2 genislikte bir register dosyasi olarak da kullanilabiliyor. Boyle olunca aslinda yukarida verdigim, is basina dusen register miktarini da, bazi durumlarda x2 olarak da arttirmayi mumkun hale getiriyor. Yani baski gerektiginde daha da azaltilabiliyor.
- Wave64 artik iki tane cycle'da calisan Wave32'e indirgenmis durumda.. Ama bunun daha guzeli, ozellikle iki pespese komut arasindaki etkilesimden dolayi bir sonrakinin bekletilmesi gerektigi durumlarda wave64 aslinda o beklemeleri biraz daha efektif hale getirmis oluyor. O yuzden Wave64'ler bile hala GCN'deki haline gore daha avantajli.
- Trigonometri/x^y tipi komutlar hala 4 cycle sure aliyor, ama kendinden sonra gelen komutlari etkilememesi durumunda, obur komutlarin calismasini bloke etmiyor. Bu sekilde en azindan bu komutlar ile scalar/vektor komutlari ile paralel calistirilabiliyorlar. Bu GPU'lara da "siralamadan bagimsiz calistirma" (out-of-order execution) ozelliginin yavas yavas geliyor olmasi demek..
- Hafizadan okuma ve yazma islemleri icin bir yerine artik iki ayri unite var. Bunlar da birbirinden ayrildigi icin yazma/okuma gerekliligini dengeleyen shaderlar burada cok daha verimli calisabiliyorlar..
Iste tum bu degisiklikler aslinda RDNA hesap unitelerinin, GCN hesap unitelerine gore cok daha verimli ve efektif kullanilabilmesine olanak sagliyor. Bu acidan bakildiginda AMD'nin gosterdigi su asagidaki slayt'a bakarsaniz, bazi is paketleri icin iyilesme cok ama cok drastik... ve iyilesmeler sadece bununla da sinirli degil...

Hesap Unitelerini beslemek...
GCN'in yukarida yazdigim sorunlari disinda aslinda bir baska buyuk problemi daha var. O da hafiza erisim yetersizligi. Yukarida verdigim orneklerde hesap unitesi uzerindeki tum isler hafiza erisimi yaptigi zaman bekleme durumunda kaliyor gibi yazmistim. Ama durum tam olarak da oyle degil: Ana hafizadan once aslinda arada her CU'nun sahip oldugu bir L1 hafiza cache'si, onda olmayan datalar icin bir de tum CU'larin bagli oldugu oldukca buyuk (Vega icin 4 MB) bir L2 hafiza cache'si var. Ulasilmak istenen data her ikisinde de olmamasi durumunda aslinda ana hafizaya ulasilmasi ihtiyaci oluyor. Ama ona ragmen GCN mimarisi tasiyan grafik kartlarina baktiginizda genel olarak mevcut bandwidth'in yine de hep yetmedigi goruluyor. Bunun disinda aslinda ana hafizaya erisim yapildigi zaman sadece istenen data degil, o datanin cevresindeki hafiza alanlari da L2 cache'e tasinir.. Eger programcilar grafik motorunu bu datayi da kullanacak sekilde verimli yazmazlarsa o zaman problemler daha da buyur ve her hesap unitesine gerekli datalar gelene kadar ALU'lar epey bos oturabilirler.
Vega serisinde hafiza bandwidth acisindan daha zorlayici olan oyun benchmarklarina baktiginiz zaman Vega mimarisinin hafiza erisim bandwidth'i arttigi zaman GPU performansinin da arttigini gorebiliyorsunuz. Buna en guzel ornek aslinda Vega-64 ile Radeon-7 gosterilebilir. Ikisi de ayni mimariyi tasimasina ragmen ve ayni clock'da calistigi durumda bile Radeon 7, Vega64'e gore %15-25 arasinda daha yuksek performans gosterebiliyor [3]. Bu fark isin dogrusu iki kat memory bandwidth'e sahip Radeon 7'nin bu compute uniteleri cok daha efektif besleyebilmesinden geliyor diye dusunuyorum. Benzer sekilde Xbox One X'deki Scorpio silikonu da aslinda 40 hesap unitesi tasiyan GCN GPU'lar icinde ~320 GB/sn bandwidth ile en yuksek memory bandwidth'e sahip GPU. R580'e gore daha eski GCN mimarisine sahip olmasina ragmen ayni miktarda hesap kapasitesi ile (6 TFlops) ozellikle 4K'yi cok daha verimli olarak calistirabildigi gorulmektedir.
Nvidia bu soruna Maxwell serisinden beridir guzel bir cozum bulmus durumda. Nvidia cozumunde ilk once vertex/ucgenler uzerindeki islemler uygulanir ve sonra bu ucgenlerin ekranda nereye dustugu ve en ustte hangisi kaldigi belirlenir. Ikinci asamada bu gorunur olan ucgenlerin ihtiyac duydugu hafiza kaynaklari belirlenir. Ucuncu asamada ekran bu ucgenler ve ihtiyac duydugu kaynaklarin L2 cache'e sigacagi sekilde bolunur. En son asamada ise her bolunen kisim icin sirayla once kaynaklar ana hafizadan L2'e cache tasinir ve tasindiktan sonra da hesap uniteleri uzerinde islenmeye baslar. "Tile-based rasterization and binning" olarak da gecen bu mekanizmanin en buyuk avantaji, tum sistem bazinda hafiza erisimini cok efektif halde tutmakta ve hesap uniteleri ile hafiza erisimi arasindaki sureden dogan gecikmeyi ciddi sekilde azaltmaktadir. Nvidia Maxwell mimarisinden itibarek bunu cok iyi kullanmisti ve acikcasi hem mobil islemciler de, hem de desktop'da AMD'nin onune gecebilmesinde cok buyuk katkisi olmustur.. AMD de aslinda Vega serisinde benzer bir ozelligi GCN mimarisine de eklemisti. "Draw Stream Binning Rasterizer (DSBR)" olarak gecen bu metodun da benzer sekilde calisacagi aciklanmisti. Ama ya cesitli buglari oldugu icin bunu kullanima alamadilar, yada gercekten Wave64 ile buyuk bir avantaj getirmedi.
Simdi tekrar RDNA'ya donelim.. RDNA'da da, Vega ve Nvidia Maxwell sonrasinda olan GPU'lardaki bu tiled-based rendering mekanizmasi var ve cok muhtemelen AMD sonunda bunu calisir hale getirmis durumda. Ama AMD burada durmamis, daha once her CU icin ayrilmis olan L1 cache, RDNA'de x2 boyutta L0 cache olarak geliyor. Bunun yaninda her CU icin ayrilan instruction ve data cache'lerin boyutu da iki katina cikmis durumda. Bunun yaninda her 10 CU tasiyan "shader array" icin ayrilmis 128 KB boyutunda bir L1 cache var. Bu ozellikle birden fazla hesap unitesi bir arada benzer isler uzerinde calistigi zaman buyuk avantaj getiriyor. L2 cache burada artik ucuncu seviyede. Tile-based rendering disinda bir de kopyalama icin yapilan islemler icin de L2 cache kullanilabilir hale gelmis. AMD'nin dedigine gore artik L2 cache'i komple bosaltma durumlari tum GCN mimarisine sahip GPUlar ile karsilastirildiginda cok cok azalmis durumda..

RDNA'nin hafiza erisim avantajlari sadece bunlarla da sinirli degil: GCN mimarisinde renk ve derinlik bilgisi bir sikistirma islemi uygulandiktan sonra ana hafizaya yazilir ve ana hafizadan tekrar okunmasi durumunda da sikismis dataya acma islemi uygulanir. Tum chip icinde ise data bu gercek hali ile transfer edilir. RDNA'da ise chip icindeki neredeyse her blokun (hesap uniteleri de dahil) bu datalari sikistirma ve acma yetisi var. Boyle olunca chip icindeki data transferleri de sikistirilmis data uzerinden yapildigi icin mevcut bandwidth daha da verimli kullanilabilir hale gelmis. Bunun yaninda tabii sikistma algoritmalarini da onceki mimarilere gore gelistirdikleri icin, o acidan da ektra bir avantaji var. Bu ikisi bir araya geldiginde tile-based rendering cok daha verimli hale geliyor, cunku L2 cache'de tutulan bilgiler sikistirilmis hali ile tutulacagi icin ekrani daha az bolume ayirmasi da yetecek demektir.
Performans kismina girmeden once eger mimariler ve gelismeler hakkinda detayli bir sunum ve yazi okumak isterseniz su iki web linki mutlaka okumanizi oneriririm [4, 5].
Peki ya Performans...
Yukarida anlattigim gibi AMD bu yeni mimari ile iki problemi ayni anda cozmus: Hem uniteleri ozellikle tek isi cok daha verimli yapacak, beklemeleri azaltacak ve daha cok is atayabilecek hale getirmis, hem de ozellikle grafik islemlerinde bu unitelerin ihtiyac duyacagi datayi da unitelere verimli besleyecek mekanizmalari yerine koymuslar..
Genel olarak PC oyun benchmarklarina bakildiginda 7.5 TFlops/448 GB/sn hafiza bandwidth'e sahip Radeon 5700 grafik karti, 12.5 TFlops/484 GB/sn'e sahip Vega 64 ile ya esit peformans yada %20'e kadar bir performans artisi sunmus gorunuyor [6, 7]. Yani AMD yaklasik ayni hafiza bandwidth ile neredeyse 7.5 Tflops'luk bir RDNA GPU ile 12.5 TFlops'luk bir GPU'yu gecer hale gelmis, en azindan mevcut oyun motorlari icin. Bu da GCN ile karsilastirildiginda, ayni speclerdeki GPU icin RDNA ile %80'lik bir performans artisini alinabildigini gosteriyor. Ustelik de bu GCN mimarisinin en iyi ve en gelismis olani ile karsilastirildiginda.. Unutmayin PS4 ve XB1 o mimariye gore uc generasyon daha eski...
Bir diger faktor ise hafiza bandwidth gereksinimi. Bir baska benchmark'a [8] bakildiginda neredeyse hic bir oyun icin 5700XT'nin saat frekansi iyice artmadan bir hafiza bandwidth erisimi sinirlamasi gozukmuyor. Hafiza erisim miktari ayni olmasina ragmen GPU saat frekansi arttirilmasi durumunda %12-%18 arasinda bir ek hizlanma da goze carpiyor ve sanki sinirlamanin pixel fillrate'den oldugu gorunuyor. Yani pixel fillrate sinirladiktan sonra, extra hesap gucu de daha fazla bir hizlanma getirmiyor. Buradan ters tarafa gidersek, aslinda 5700'un sahip oldugu memory bandwidth gereksiz yuksek oldugunu gosteriyor ve 5700'un yaklasik ~380 GB/sn ile de benzer performans alinabilecegini gosteriyor. O acidan da dusunuldugunde aslinda hafiza kullanimi da %20-25 daha efektif olmus durumda GCN'in en iyi mimarisine gore.
AMD bu sefer becermis sanki....
Next-Gen Konsollar..

Uzun surdu ama beni en cok heyecanlandiran kisma geldik. Burada aslinda mevcut konsollardaki GPU'lar ile birebir bir karsilastirma yapmak maalesef mumkun degil. Ama isin ozu PS4 ve XB1'de bulunan 2. generasyon GCN'den, muhtemelen 1. ile 2. generasyon arasinda bir yerdeki RDNA'a atliyor olacagiz. Vega ile karsilastirmaya bakildiginda %20 daha az hafiza bandwidth ile neredeyse %80 iyilestirme getiren bir mimari, ondan cok daha eski bir mimariye sahip GPU'lar ile karsilastirildiginda daha da fazla bir iyilestirme getirecegi kesin gibi. O yuzden misal 6 Tflops ve ~320 GB/sn sahip bir RDNA GPU ile muhtmelen X1X'e gore rahat x2 performans alinmasi gayet mumkun duruyor.
Peki yeni konsollarin RDNA spesificasyonu ne olabilir: Isin dogrusu burasi biraz destekli kestirim. Ama gecmise bakarak ve su anki yari-iletken performans/fiyatlandirmaya bakarak bir tahmin yapabiliriz. Bugun RDNA/Navi ve Zen2'nin temel aldigi process teknolojisi 7nm. Su an Sony ve MS'un konsollarinda kullanilan islemci yongalari ise 14/16 nm teknolojiyi kullaniyor. Su anda okudugumuz kadari ile 7nm uretim, 14/16nm uretime gore %30-50 arasinda daha pahali [9]. Bu da Sony ve MS mevcut konsollarin maliyetini sadece makul miktarda arttirmayi hedefliyorsa istiyorsa, o zaman chip boyutunu %25-%35 azaltmasi demek oluyor. Bu da Sony icin chip boyutunu 220-250mm2'ye, MS icinse 240-270 mm2 civarlarina koyuyor.
Su an piyasada olan Navi10'un chip boyutu 251 mm2, Zen2 islemcisinin de 80mm2 civarinda. Yani aslinda boyutlari kucultmuyor olsak, ikisinin toplami PS4Pro islemcisi ile ayni seviyeye geliyor. Ama boyut kucultuyorsak, bu her iki mimariyi de bir miktar kirpmak zorunda oldugumuz anlamina geliyor. Buradaki ilk hedef Zen2'nin 32 MB'lik cok buyuk L3 cache'si olacaktir. Simdilik sizan bilgiler de Zen2'de L3 cache'in next-gen konsollar icin 8 MB'a indigi yolunda. Eger bu dogru ise 80mm2 yaklasik 40mm2'e indi demektir. Ama hala en az bir 40 mm2 eksigimiz var. Benim tahminim bugun Navi10'larda olan 10 hesap unitesi tasiyan 4 shader array'in yeni generasyon konsollarda 12 hesap unitesi tasiyan 3 shader array'e inecegi yonunde. Su anda giris seviye olan Navi14 GPU icin de benzer bir yapi oldugu konusuluyor [10] ve ben next-gen konsollara da bu sekilde girecegini dusunuyorum. Bu sayede Navi10'da olan chip layout'u da cok degistirmeden ve performanstan da cok odun vermeyen bir konsol SoC'u AMD cikarabilecektir (Maalesef geometri isleme dortte bir azalacaktir ama).
Bir diger tahminim ise uretimden cikan chiplerin buyuk cogunlugunu kullanabilmek icin 36 hesap unitesinden sadece 32 tanesinin kullanilabilir durumda olmasi (Ps4Pro ve X1X'de de bu sekilde 4 tane hesap unitesi kapalidir). Yine sizintilara bakarsak GPU'nun hizinin 1.8 Ghz olacagi ongoruluyor ki bu 32 hesap unitesi ile ~7.37 Tflops islem yetenegi demek. Bu hesap gucunu destekleyecek render-operator sayisi da muhtemelen 60 olacak (64 yerine) ve cok muhtemelen memory bandwidth'de 384 GB/sn civarinda olacak. Boylece mevcut konsollardaki 14 Gb/sn moduller yerine Sony ve MS'in daha hesapli olan 12 Gb/sn GDDR6 modulleri kullanmasi da olanakli hale gelecektir. Ozetle 5700 serisi grafik karti performansina bakiyoruz aslinda..
Simdi az once 6 Tflops/320 GB/sn memory bandwidth'e sahip bir GPU'nun X1X'e gore x2 hizli olacagini soylemistik.. 7.4 TFlops, bunun uzerine extra bir %25 performans daha koyuyor. Yani X1X'e gore goreceli olarak x2.5 bir performans farki olacagi soylenebilir.
Bu yukarida yazdiklarimdan daha iyisi de olmasi olasi tabii.. Mesela 7nm EUV ile ayni alana %20'e yakin bir ek transistor paketlenebilecegi soyleniyor [11]. Buda 36 CU yerine 48 CU'ya cikma anlamina gelebilir.. Her iki sirkette bu sekilde hesap unitesi sayisini arttirma yoluna gidebilirler. Ama PC'deki benchmarkin gosterdigine gore bu tip artislar beraberinde memory bandwidth'in de pixel fill-rate'in de arttirilmasini gerektiriyor. Bu baglamda o zaman ya daha henuz piyasada yeni yeni gozukmeye baslayan 16 Gb/sn moduller kullanilmasi lazim, yada bus genisliginin 320/384 bit'e cikmasi.. Bu artisin getirecegi maliyet disinda, artacak sogutma gereksinimi de cabasi.. Tum bunlarin konsol fiyatlarini ciddi arttiracagi icin ben pek ihtimal vermiyorum, ama kimbilir belki bir supriz yaparlar..
x4 Pek Mumkun Degil Sanki.. Ama ya "Secret Sauce"'lar

Bir baska performans iyilestirici ozellik ise x2 hizda islem yapmaya olanak veren "rapid-packed" math. Bu metot su anda bu generasyon piyasada olan konsollardan sadece Ps4 Pro'da (ve tabii Switch de) var ve bu teknigi belli islemler icin bir kac oyun motorunun kullandigini da biliyoruz. Buradaki ozellik ise vektor islemlerde ayni clock icinde bir tane single-precision kayan-nokta aritmetik islemi yapmak yerine iki tane 16 bit half-precision kayan-nokta islemi yapilmasi. Bu ozelligin guzel tarafi ise hem extra bir hafiza erisimi, hem de extra bir register alani istememesi.. Yani bu islemi yapacak silikon alani disinda extra bir gereksinim yok. Bu ozellik, grafik motorlarinda screen-space post-process islemlerini cok hizlandirabilmesi yaninda derin ogrenme tabanli metodlari da yine iki kat hizlandirdigi biliniyor ve AMD bu rapid-packed math icin RDNA'e epey bir yeni ozellik eklemis durumda.. Bunun da developerlarin bahsettigi kadari ile yine ek bir %10-%15 arasinda bir ek hizlanma getirecegi soyleniyor. PC uzerinde hem Vega, hem RDNA grafik kartlari, Nvidia tarafinda ise Maxwell'den beri desteklendigi icin artik cok muhtemelen yeni konsollarda da standart ozellik olarak desteklenecektir. Buradan da bir x1.1-x1.15 arasi kazandik.
Daha "secret sauce"'lara bile gelmeden bu ikisinin getirecegi iyilestirmeler ile X1X'e gore performans artisi x3 ile x3.5 arasina cikardi bile.
Genelde hem Sony hem MS, aslinda islemleri bir miktar daha hizlandirmaya olanak verecek eklemeler de getiriyor konsollarda. Benim aklima ilk gelen Sony'nin PS4Pro'da getirdigi checkerboard islemlerini hizlandiracak eklemeler ve MS'un da Scorpio'ya getirdigi hafiza uzerindeki baskiyi azaltacak teknikler.. Her iki konsol ureticisi bu tip iyilestirmeler ile bu geride kalan %15-%30 extra iyilesmeyi getirebilir.. O zaman, evet, X1X'e gore x4 iyilesmeyi gormus oluruz.
Sonuc olarak x4 iyilesmeyi basaramasalar bile ona yaklasacaklari kesin.. Bu GPU'ya uygun bir CPU ile su an zaten cok guzel gorununen bir cok oyunun cok rahat 4K60 calismasi mumkun hale gelecek bence... Ama CPU tarafindaki iyilesmeler de aslinda yeni konsollarin bu noktada kalmayacagini, muhtemelen 1080p120 ve 1440p90'i da cok rahat yapabileceklerini gosteriyor.. Ustelilik de next-gen oyunlar icin de daha hala epey bir gelisme alani da kalacak sanki. Sony ve MS'un bahsettigi 8K'yi bilmem, ama hem 4K icin hem de VR sistemler icin cok ideal konsollar geliyor artik..
ve Son Olarak Ray-Tracing...

Konsol uretici tarafina gelirsek MS cok net olarak Xbox Scarlett'de donanim olarak ray-tracing hizlandirici olacagini soyledi. Bu zaten beklenen birseydi, cunku daha ortada hic bir donanim yokken Windows 10'a DXR altinda ray-tracing hizlandirici bir DX eklenti arayuzu aciklamislardi ve cok kisa bir sure sonra da Nvidia ile beraber Turing serisi tanitirken, DXR icin baska donanimlar da olacagini vurgulamislardi. O yuzden next-gen Xbox'da donanim ray-tracing olacagi kesin gibi.
Sony tarafina gelirsek donanim ray-tracing'in olup olmayacagi hala cok kesin degil.. Her ne kadar okudugumuz bir cok yazida Sony tarafinda da donanim ray-tracing destegi olacagi yazmasina ragmen, cikan sizintilar Sony'nin daha vanilla bir Navi10 tasidigi yonunde ve PS5 ana mimari Mark Cerny ile yapilan soyleside de Cerny grafik ray-tracing'e pek vurgu yapmadan, next-gen Playstation'da raytracing'in audio icin olacagini vurgulamisti. AMD'nin son cikardigi Navi whitepaper'da da ayni "raytracing audio" ozelligi hakkinda bilgi veriliyor, yani AMD tarafinda da aciklama Sony'nin acikladiklari ile paralel simdilik [4]. Tabii bu daha AMD'nin donanim raytracing ozelligini tanitmadigindan da olabilir.. O yuzden PS5'de donanim ray-tracing destegi hala tam net degil.
Ozetle..
Bir sonraki yazida da CPU'ya geliyoruz.. Orada da mevcut konsollara gore saglam iyilesme var.. Orasi da heyecanli :)
[1] https://www.tomshardware.com/news/amd-arcturus-vega-gpu-support,39935.html
[2] https://en.wikipedia.org/wiki/Graphics_Core_Next
[3] https://www.anandtech.com/show/13923/the-amd-radeon-vii-review/18
[4] https://www.amd.com/system/files/documents/rdna-whitepaper.pdf
[5] https://gpuopen.com/wp-content/uploads/2019/08/RDNA_Architecture_public.pdf
[6] https://www.anandtech.com/show/14618/the-amd-radeon-rx-5700-xt-rx-5700-review
[7] https://www.eurogamer.net/articles/digitalfoundry-2019-amd-radeon-rx-5700-rx-5700-xt-review-head-to-head-with-nvidia-super
[8] https://www.guru3d.com/articles-pages/asus-radeon-rx-5700-xt-rog-strix-review,1.html
[9] https://www.icknowledge.com/news/Technology%20and%20Cost%20Trends%20at%20Advanced%20Nodes%20-%20Revised.pdf
[10] https://wccftech.com/amd-navi-14-gpu-radeon-rx-graphics-card-performance-leak/
[11] https://www.techspot.com/news/80237-tsmc-7nm-production-improves-performance-10.html
[12] https://developer.nvidia.com/vrworks/graphics/variablerateshading
[13] https://www.nvidia.com/en-us/geforce/news/nvidia-adaptive-shading-a-deep-dive/
Videolar
Metro Exodus
Control
Path-Tracer Minecraft
Star Wars Demo
